Intro-HPC-workshop
What is High Performance Computing?
High Performance Computing (HPC) refers to the use of powerful computers, often organized into clusters, to perform large-scale calculations or process massive amounts of data quickly.
HPC is used when a task is:
- Too large for a desktop to handle in a reasonable time
- Too memory-intensive to fit in a typical computer
- Designed to run faster when split into smaller parts and executed in parallel
Examples include:
- Simulating physical systems (e.g. climate, fluid dynamics, materials)
- Processing large datasets (e.g. genomic sequencing, satellite imagery)
- Training machine learning models
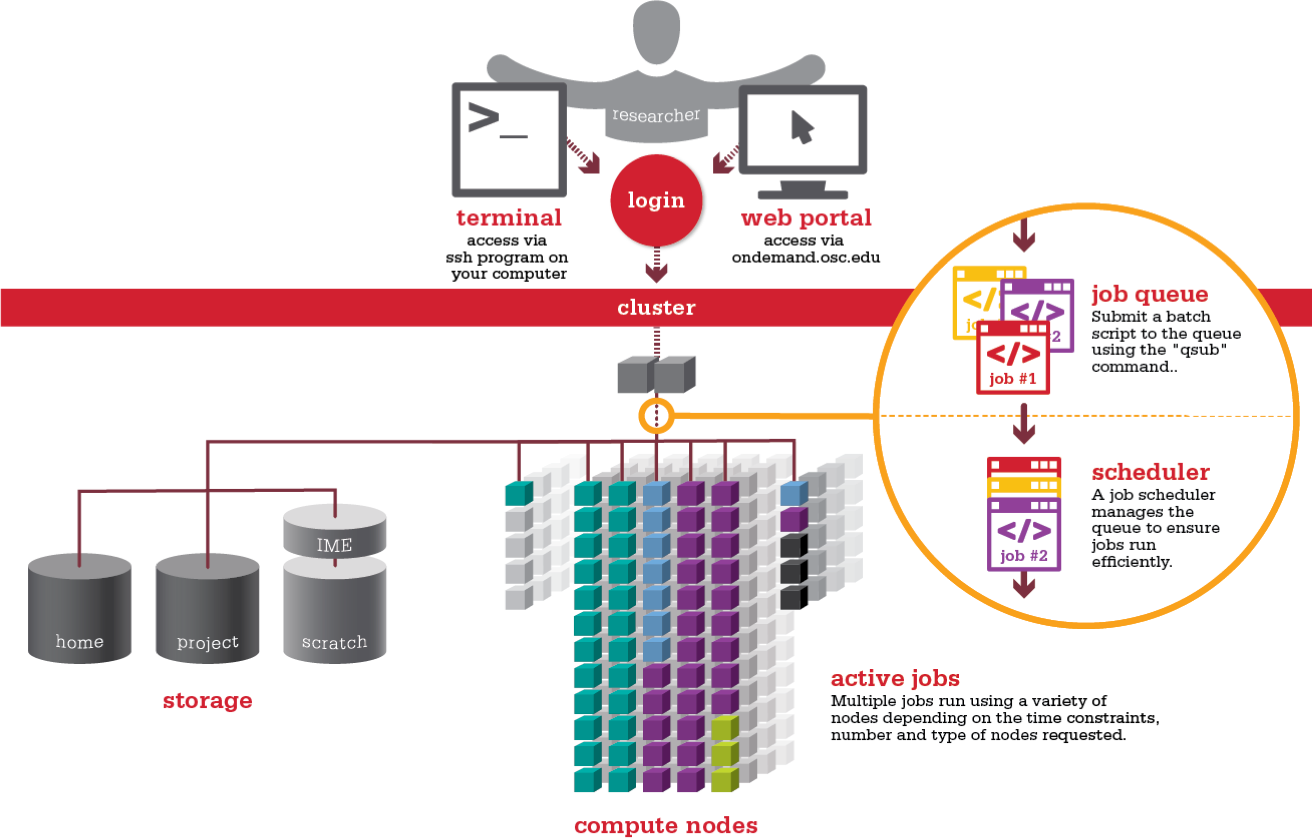
Most HPC systems have a layout something like the following:
](https://www.osc.edu/sites/osc.edu/files/staff_files/kcahill/Cluster_diagram_node.png)
HPC vs Desktop Computers
| Feature | Desktop Computer | HPC System |
|---|---|---|
| CPU cores | 2–16 | 100s–100,000s (across nodes) |
| Memory (RAM) | Up to 64 GB | Multiple terabytes (cluster-wide) |
| Storage | Local HDD/SSD | Shared high-performance storage |
| Networking | Ethernet/Wi-Fi | High-speed interconnect |
| Parallelism | Limited | Fundamental design feature |
| Job execution | Manual run | Scheduled jobs via a queueing system |
What HPC Resources Are Available to Me?
| System | Kind | Access | Notes |
|---|---|---|---|
| NCI | HPC cluster | Australian researchers | Annual call for applications |
| WSU Cluster | HPC Cluster | Academic Supervisor / ITDS (ACE - SSTaRS) | No requirement for formal applicatons, or time limits associated with accounts or projects |
| Azure / GCloud / AWS | Cloud computing | Anyone with a credit card | On demand computing as a service |
Hardware
Different Nodes
An HPC system is made up of nodes, which are individual servers connected into a larger system. Common node types include:
- Login node: Where users connect via SSH, prepare job scripts, and submit jobs (not for computation). In our case, the Wolffe System.
- Compute node: Where jobs actually run; each contains multiple CPU cores and memory.
- GPU node: Includes graphics processing units for massively parallel tasks (e.g. deep learning).
- High-memory node: For jobs that require large RAM (hundreds of GB to multiple TB).
Note. The only system you would normally be connecting to is the Login Node - at no point should you be connecting to individual nodes and directly running jobs on them
Storage Options
HPC environments use different storage areas optimized for different tasks:
- Home directory:
- Persistent
- (often) Backed up (in our case, it isn’t - prepare accordingly!)
- Best for code, scripts, small files
- Scratch space:
- Temporary, fast
- Not backed up
- Used during job execution for intermediate files
- Often purged automatically after a period (e.g. 30 days)
- Project or group storage:
- Shared among a research group
- (often) Backed up (in our case, it isn’t - prepare accordingly!)
- Often quota-managed
- Archive storage:
- Long-term, low-cost
- Usually slower to access
- Best for storing completed results or raw data that’s infrequently used
Interconnect
The interconnect is the high-speed network connecting all the compute nodes in the cluster.
Unlike regular Ethernet (like what you’d use at home or in an office), HPC systems use specialized networks such as InfiniBand or Omni-Path to:
- Move data between nodes quickly
- Enable parallel programs to work efficiently (e.g. a simulation split across 64 nodes needs to share data during runtime)
- Minimize latency (delay) and maximize bandwidth (amount of data per second)
Think of it like having a private, ultra-fast highway between every machine, rather than a shared local road — which keeps everything moving quickly and smoothly when the workload is distributed.
Clusters
An HPC cluster is the full system: a collection of compute nodes, login nodes, storage, and interconnects, all managed centrally.
Users submit jobs to a scheduler, which:
- Places jobs in a queue
- Allocates appropriate resources (e.g. number of CPUs, memory, time)
- Runs jobs when resources become available
Clusters allow multiple users to run large jobs at the same time, efficiently sharing resources.
Software
HPC systems are generally accessed through the command line via SSH. Users don’t run jobs directly, but instead write job scripts that are submitted to a job scheduler.
Job Schedulers
Common job schedulers:
- SLURM (widely used in research and academia)
- PBS (older but still in use)
These schedulers manage when and where jobs are run on the cluster.
A basic SLURM script might look like this:
#!/bin/bash
#SBATCH --job-name=myjob
#SBATCH --ntasks=4
#SBATCH --time=00:30:00
#SBATCH --output=output.log
module load python/3.11
python myscript.py
Key points:
- Resources are requested with
#SBATCHlines - You can load software environments with
module load(we will come to this soon!) - Output goes to a file instead of appearing on your screen. Can also re-direct errors to a separate file
- Scripts are run from the Login Node
An example of how the user connects to login node, and then the scheduler distributes the jobs to the relevant queues is below: